Low-level PDF manipulation for F#
13 Mar 2017
The code contained here consists of a module
for manipulating PDF objects (pdf.fs), and a very simple
parser for Adobe Font Metrics files and glyph-lists
(afm.fs).
Things it can do:
Create arbitrary PDF documents.
Read objects from PDF documents (although it does not support parsing or decompression of content streams – you need to implement this yourself).
Deep-copy objects from one PDF document to another (e.g. to use a page of one document as an image or background in another).
Calculate text sizes given a string, a point size, and an Adobe Font Metrics file.
PDFs of arbitrary complexity can be created, but you may find it useful to wrap the module in something higher-level and more specific to your needs.
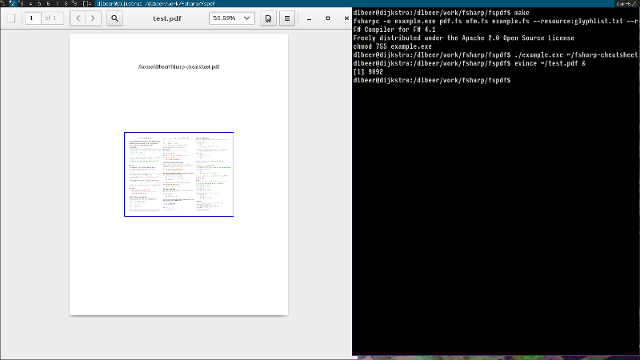
Included is an example program (example.fs), which takes
as arguments the name of an input and an output PDF file. Page 1 of the
input file is extracted, and then a single-page output file is created
which shows page 1 of the input file scaled down and centered in the
middle of the page, with a blue border and a centered caption above
it.
Building the example
The included code should be able to be run on nearly any system. It has no dependencies outside the .NET standard library. If you’re on a Linux system with mono and the F# compiler installed, type “make” to build.
If you’re building manually, select all F# files for building, with example.fs last in the list. You will also need to include glyphlist.txt and Times-Roman.afm as assembly resources. The names of these resources should be the same as their filenames.