Efficient aggregate computation on B+Trees
10 Feb 2011
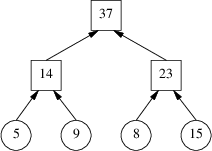
Many applications use B+Trees or variants thereof to store large sets of ordered data. These provide lookups, modifications and deletions of individual records in O(log n) time.
Often, it’s useful to be able to produce summary or aggregate
information on all or part of a dataset. In SQL, these operations would
correspond to the evaluation of aggregate functions like
MIN, MAX, SUM, AVG
or COUNT.
When computing these summaries, usually the appropriate range of the dataset must be enumerated in O(k log n) time, where k is the number of records in the range (or O(k + log n) time if the properties of B+Tree data organization are exploited.
This article describes an enhancement to the B+Tree data structure which enables certain types of summaries to be computed on arbitrary contiguous subsets of the tree in O(log n) time. The time complexities of the usual B+Tree operations for insertion and deletion are not affected, and still run in O(log n) time.
Assumptions and prerequisites
In this document, the word record will be used to refer to an item of data stored in one of the slots of a leaf-node. The B+Tree is augmented by adding an additional data field to each node, known as a summary. Two operations are associated with summaries:
SUMMARIZE(record) -> summary-
This is a function that produces, from a record, a summary data type.
COMBINE(summary, summary) -> summary-
Given the summaries of two subsets of records, produce a summary of the union of the subsets. This function may assume that the two subsets are disjoint, and that the union of them is contiguous. The function must be associative (that is,
COMBINE(A, COMBINE(B, C)) = COMBINE(COMBINE(A, B), C)).
Both of these functions must be computable in O(1) time. A special
summary value should be defined as the summary over the empty set. This
value will be referred to as ZERO in the following
description.
Suppose, for example, that we had a B+Tree containing records which
had an integer field called foo, and that we wanted to be
able to efficiently compute sums of foo over arbitrary
contiguous ranges. Then, we would define summaries as follows:
The summary type would simply be an integer.
SUMMARIZEwould extract thefoofield from a record and return it.COMBINEwould be defined asCOMBINE(A, B) = A + B.ZEROwould be the integer 0.
We will use the following notation to refer to different fields in a B+Tree:
n.child[i]refers to the ith pointer to a sub-node from a non-leaf node.n.record[i]refers to the ith record in a leaf node. In a non-leaf node, it is the key of the smallest item in the ith subtree. For simplicity, we assume that keys are just records which have only their key fields filled in.n.is_leafis a boolean value which is true for leaf nodes.n.sizeis either the number of child pointers (for non-leaf nodes) or the number of records (for leaf nodes).n.summaryis a summary object, as defined above.
Maintenance of summary data
To maintain the summary objects in each node, the usual B+Tree insert
and delete algorithms need to be modified. We introduce a new operation
on a B+Tree node called UPDATE-SUMMARY(n), defined as
follows:
UPDATE-SUMMARY(n):
IF n.is_leaf:
s := SUMMARIZE(n.record[0])
FOR i := 1 TO n.size - 1:
s := COMBINE(s, SUMMARIZE(n.record[i]))
n.summary := s
ELSE:
s := n.child[0].summary
FOR i := 1 TO n.size - 1:
s := COMBINE(s, n.child[i].summary)
n.summary := sGiven that the SUMMARIZE and COMBINE
operations run in O(1) time, and n.size has a fixed upper
limit, it is evident that UPDATE-SUMMARY also runs in O(1)
time.
After any modification to the B+Tree, the summaries computed for any altered node are invalidated, as well as the summaries for ancestors of altered nodes. They must be recomputed by a post-order traversal (because higher-level node summaries depend on the summaries of their children) over the affected nodes. Since B+Tree insertion and deletion affect at most O(log n) nodes, the time complexities of these operations are not affected by the need to maintain summary data.
Insertion
We first define a helper function, FIND-LE(n, key),
which returns the index of the largest item or subtree key in a node
which is not greater than the given key. If no such item exists, it
returns 0. For non-leaf nodes, this index indicates the subtree where we
might find the given key.
FIND-LE(n, key):
i := 0
WHILE i + 1 < n.size AND n.record[i + 1] <= key:
i := i + 1
RETURN iWe also define a low-level operation,
INSERT-ITEM(n, pos, record, child), which places the given
data items at the given slot in a node. If the node is full, it is split
and the upper half is returned as a new node. When invoked on leaf
nodes, the child argument is NIL:
INSERT-ITEM(n, pos, record, child):
orphan := NIL
-- If the node is full, split it in half. Keep track of the new
-- upper half, because there is not yet a pointer to it, and we
-- need to return one.
IF n.size >= MAX-SIZE:
orphan := ALLOC-NODE(n.is_leaf)
orphan.record[0:MIN-SIZE] := n.record[MIN-SIZE:MAX-SIZE]
orphan.child[0:MIN-SIZE] := n.child[MIN-SIZE:MAX-SIZE]
orphan.size := MIN-SIZE
n.size := MIN-SIZE
-- If the originally specified position is now in the upper
-- half, we need to insert into the orphan node instead.
IF pos >= MIN-SIZE:
pos := pos - MIN-SIZE
n := orphan
-- Shift the records after the specified position and insert
-- the new record.
n.record[pos + 1:n.size + 1] := n.record[pos:n.size]
n.child[pos + 1:n.size + 1] := n.child[pos:n.size]
n.record[pos] := record
n.child[pos] := child
n.size := n.size + 1
RETURN orphanNote that the usual B+Tree node-size conditions apply:
MAX-SIZE = 2 * MIN-SIZEMIN-SIZE >= 2
Having defined the necessary low-level operations, the algorithm for
inserting into a subtree is given by the algorithm
PUT-SUBTREE(n, record). Inserting into a subtree may result
in the splitting of the subtree’s root. In this case, the upper half of
the split node is returned.
PUT-SUBTREE(n, record):
i := FIND-LE(n, record)
orphan := NIL
IF n.is_leaf:
IF record < n.record[i]:
orphan := INSERT-ITEM(n, i, record, NIL)
ELSE IF n.record[i] < n:
orphan := INSERT-ITEM(n, i + 1, record, NIL)
ELSE:
n.record[i] := record
ELSE:
adoptee := PUT-SUBTREE(n.child[i], record)
-- If the inserted record is lexicographically smaller than
-- anything else in the ith subtree, the child index pointer
-- will now be incorrect. Updating it is always safe and
-- does not affect summary information.
n.values[i] := n.children[i].record[0]
IF adoptee != NIL:
orphan := INSERT-ITEM(n, i + 1, adoptee.record[0], adoptee)
-- Update summary information for nodes altered at this level
-- of the tree. Performed last so that UPDATE-SUMMARY is called
-- in a post-order traversal of modified nodes.
UPDATE-SUMMARY(n)
IF orphan != NIL:
UPDATE-SUMMARY(orphan)
RETURN orphanFinally, we define the function for insertion on the tree as a whole:
PUT(tree, record):
IF tree.root = NIL:
tree.root := ALLOC-NODE(TRUE)
adoptee := PUT-SUBTREE(tree.root, record)
-- Grow the tree if the root splits.
IF adoptee != NIL:
new_root := ALLOC-NODE(TRUE)
new_root.size := 2
new_root.record[0] := tree.root.record[0]
new_root.child[0] := tree.root
new_root.record[1] := adoptee.record[0]
new_root.child[1] := adoptee
tree.root := new_root
UPDATE-SUMMARY(tree.root)Deletion
For B+Tree deletion, we first define some non-recursive helper functions. These are invoked by the deletion algorithm to remove items from nodes, and to rebalance the tree.
DELETE-ITEM(n, index):
n.record[index:n.size - 1] := n.record[index + 1:n.size]
n.child[index:n.size - 1] := n.record[index + 1:n.size]
n.size := n.size - 1
-- Merge two adjacent children in a node. The index parameter
-- specifies the lexicographically smallest of the pair.
MERGE-NODES(n, index):
left := n.child[index]
right := n.child[index + 1]
left.record[left.size:left.size + right.size] :=
right.record[0:right.size]
left.child[left.size:left.size + right.size] :=
right.child[0:right.size]
left.size := left.size + right.size
DELETE-ITEM(n, index + 1)
FREE-NODE(right)
-- Given two adjacent children in a node, borrow the smallest item
-- from the right node and put it in the left node. The index
-- specifies the left child node.
BORROW-FROM-RIGHT(n, index):
left := n.child[index]
right := n.child[index + 1]
INSERT-ITEM(left, left.size, right.record[0], right.child[0])
DELETE-ITEM(right, 0)
n.record[index + 1] = right.record[0]
-- Borrow the largest item from the left node and put it in the
-- right node. The index specifies the right child node.
BORROW-FROM-LEFT(n, index):
left := n.child[index - 1]
right := n.child[index]
INSERT-ITEM(right, 0, left.record[left.size - 1],
left.child[left.size - 1])
DELETE-ITEM(left, left.size - 1)
n.record[index] = right.record[0]Making use of these helper functions, we can define a recursive procedure for deletion from a summarized B+Tree:
DEL-SUBTREE(n, key):
index := FIND-LE(n, key)
IF n.is_leaf:
IF n.record[index] = key:
DELETE-ITEM(n, index)
ELSE:
DEL-SUBTREE(n.child[index], key)
-- If the deleted node was the lexicographically smallest,
-- the key to the subtree will now be incorrect. Update it.
n.record[index] := n.child[index].record[0]
-- If the subtree from which we deleted is now underfull,
-- we need to rebalance the tree by either borrowing or
-- merging.
IF n.child[index].size < MIN-SIZE:
IF index > 0 AND n.child[index - 1].size > MIN-SIZE:
BORROW-FROM-LEFT(n, index)
UPDATE-SUMMARY(n.child[index])
UPDATE-SUMMARY(n.child[index - 1])
ELSEIF index + 1 < n.size AND
n.child[index + 1].size > MIN-SIZE:
BORROW-FROM-RIGHT(n, index)
UPDATE-SUMMARY(n.child[index])
UPDATE-SUMMARY(n.child[index + 1])
ELSEIF index > 0:
MERGE-NODES(n, index - 1)
UPDATE-SUMMARY(n.child[index - 1])
ELSE:
MERGE-NODES(n, index)
UPDATE-SUMMARY(n.child[index])
ELSE:
UPDATE-SUMMARY(n.child[index])Notice that in DEL-SUBTREE we update summaries on nodes
which are one level below n, rather than (as in
PUT-SUBTREE) at the same level as n. This is
because the DEL-SUBTREE function is responsible for
modifying children of n to rebalance the tree, whereas
PUT-SUBTREE would only modify n itself (by
means of splitting).
Finally, we define deletion on the tree as a whole, handling the special case where the tree must shrink (and updating the summary of the entire tree):
DEL(t, key):
IF t.root = NIL:
RETURN
DEL-SUBTREE(t.root, key)
IF t.root.size = 1 AND NOT t.root.is_leaf:
sub := t.root.child[0]
FREE-NODE(t.root)
t.root := sub
ELSEIF t.root.size = 0:
FREE-NODE(t.root)
t.root := NIL
ELSE:
UPDATE-SUMMARY(t.root)Evaluation of summary queries
To aid the selection of arbitrary ranges, we define a new type called a range selector. A range selector is a function which takes as its argument a record key, and returns -1, 0 or 1 to indicate whether the record is before, in or after the requested range. Ranges defined in this manner must be contiguous.
It’s possible to define ranges by other means (for example, by providing the keys of the interval endpoints), but range selectors provide the most general means possible, allowing any combination of open or closed interval endpoints to be specified.
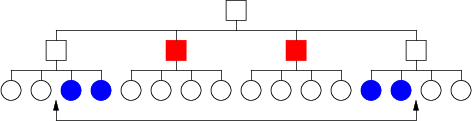
Summary evaluation is defined in terms of subtrees, and there are four cases in terms of our knowledge of the relationship between a given range and a given subtree:
- the range is known to contain the entire subtree
- the range is known to start before the smallest item in the subtree
- the range is known to end after the largest item in the subtree
- nothing is initially known about the range
Case 1 is the easiest to handle - if the range is known to span the the entire subtree, then just return the precomputed summary field for that subtree. This is evidently an O(1) operation.
Computing a summary over a leaf node is a special case orthogonal to the four cases given above. We define a single function to handle it:
SUM-LEAF(n, range):
sum := ZERO
FOR i := 0 TO n.size - 1:
IF range(n.record[i]) = 0:
sum := COMBINE(sum, SUMMARIZE(n.record[i]))
RETURN sumThis function also runs in O(1) time, as n.size has a finite upper bound.
Cases 2 and 3 are the next simplest to analyse. They can be computed by the following functions:
-- Compute the summary of all records within subtree n which fall
-- within the range given. We know in advance that this range
-- starts before the smallest item in the subtree.
SUM-BEFORE(n, range):
IF n.is_leaf:
RETURN SUM-LEAF(n, range)
-- Find the last subtree which contains some records in the
-- range.
last := 0
WHILE last + 1 < n.size AND range(n.record[last + 1]) < 1:
last := last + 1
-- Since the range is contiguous, we infer that all subtrees
-- before the last one are completely contained inside the
-- range.
sum := ZERO
FOR i := 0 TO last - 1:
sum := COMBINE(sum, n.child[i].summary)
RETURN COMBINE(sum, SUM-BEFORE(n.child[last], range))
-- Compute the summary of all records within subtree n which fall
-- within the range given. We know in advance that this range
-- ends after the largest item in the subtree.
SUM-AFTER(n, range):
IF n.is_leaf:
RETURN SUM-LEAF(n, range)
-- Find the first subtree which contains some records in the
-- range.
first := 0
WHILE first + 1 < n.size AND range(n.record[first + 1]) < 0:
first := first + 1
-- Since the range is contiguous, we infer that all subtrees
-- after the first one are completely contained inside the
-- range.
sum := SUM-AFTER(n.child[first], range)
FOR i := first + 1 TO n.size - 1:
sum := COMBINE(sum, n.child[i].summary)
RETURN sumBoth of these functions have similar structure: an amount of work bounded by the relatively small limit of the node size, and a single recursive call which descends the tree. The time complexity of each of these functions is therefore O(h), where h is the height of the subtree. They are therefore O(log n) in the size of the subtree.
Finally, we’re ready to handle case 4. We do this in a similar way - identify the first and last subtrees spanning the range, compute their summaries, and add to the precomputed summaries of the subtrees in the middle:
SUM-OVER(n, range):
IF n.is_leaf:
RETURN SUM-LEAF(n, range)
-- Find the first subtree which contains some records in the
-- range.
first := 0
WHILE first + 1 < n.size AND range(n.record[first + 1]) < 0:
first := first + 1
-- Find the last subtree which contains some records in the
-- range.
last := first
WHILE last + 1 < n.size AND range(n.record[last + 1]) < 1:
last := last + 1
IF first = last:
RETURN SUM-OVER(n.child[first], range)
sum := SUM-BEFORE(n.child[first], range)
FOR i := first + 1 TO last - 1:
sum := COMBINE(sum, n.child[i].summary)
RETURN COMBINE(sum, SUM-AFTER(n.child[last], range))Aside from the base case, which is delegated to the O(1) function
SUM-LEAF, two other cases may be encountered while
executing. Either we make one recursive call to SUM-OVER,
descending the tree, or two calls - one to SUM-BEFORE and
one to SUM-AFTER. In either case, the running time is O(h)
in the height of the subtree (and thus O(log n) in the number of items
in the subtree).
For completeness, the top-level function for computing a summary of a slice of the tree is:
SUM(t, range):
IF t.root = NIL:
RETURN ZERO
RETURN SUM-OVER(t.root, range)Enhancement to the basic algorithm: lazy updates
As described above, the algorithms for computing summaries are O(log
n) in the worst case. In same cases, the operations COMBINE
and SUMMARIZE may be relatively expensive, and it might be
that summaries are computed infrequently, or over some small subset of
the tree. If so, performance may be improved by using lazy updating of
summary fields.
Rather than recomputing summaries as you modify the tree, simply
invalidate them by setting them to NIL. Then, you need to modify the
summary computation algorithms so that rather than just fetching the
summary field of a node, they use a memoizing wrapper
function, GET-SUMMARY:
GET-SUMMARY(n):
IF n.summary = NIL:
sum := ZERO
IF n.is_leaf:
FOR i := 0 TO n.size - 1:
sum := COMBINE(sum, SUMMARIZE(n.record[i]))
ELSE:
FOR i := 0 to n.size - 1:
sum := COMBINE(sum, GET-SUMMARY(n.child[i]))
n.summary := sum
RETURN n.summaryUsing this method has the disadvantage of greatly increasing the
first time to compute a summary (O(n) the first time a subtree is
summarized). On the other hand, the insertion and deletion methods no
longer have to invoke the presumably expensive
UPDATE-SUMMARY function for each record inserted.